Two inference apps running the same GGUF model on the same Mac can differ by 37% in speed. With no format change, no model change, not on a different app. Seeing these results, the answer to a question “GGUF vs MLX” looks easy: opt for MLX.
But that doesn't make it faster for every workflow, because generation speed is not what you spend most of your time waiting for.
So how can you make your local LLM faster on macOS?
TL;DR
- MLX is faster for long outputs (250+ token replies, summaries): generation speed outpaces the slower prefill start once output gets long enough
- GGUF is faster on short tasks (Q&A, tool calls, classification): on M5 Max, GGUF finished a classification in 1.0s vs 2.2s for MLX on the same runtime
- "4-bit" is not the same quality: GGUF Q4_K_M has 4.7x lower perplexity degradation than MLX uniform 4-bit at nearly the same file size
- On M1/M2: convert MLX weights from bf16 to fp16. Recovers 40-70% of the prefill penalty with no quality loss. Or use GGUF in Atomic Chat: no conversion needed.
- The runtime matters more than the format: Ollama is 37% slower than LM Studio on the same GGUF engine; oMLX is 2.2x faster than LM Studio on MLX
- Atomic Chat runs GGUF up to 40% faster than stock llama.cpp via MTP (Multi-Token Prediction)
- On M3+ with casual workloads, the gap between formats is small – pick whichever model you can find
GGUF vs MLX: key differences
| GGUF | MLX | |
|---|---|---|
| Format | Single .gguf binary file | Directory: safetensors shards + config.json + tokenizer files |
| Runtime | Atomic Chat, llama.cpp, LM Studio, Ollama, anything compatible | Apple MLX framework only |
| Platforms | Mac, Linux, Windows, cloud GPU, CPU-only | Apple Silicon only (M1+) |
| Ships with | Weights + tokenizer + chat template + metadata | Weights + separate tokenizer + config |
| Quantization options | Q4_K_M, Q5_K_M, Q6_K, Q8_0, and more | Uniform 4-bit by default; mixed recipes available |
| New model availability | Within hours of a model release | Days to weeks after release |
GGUF and MLX are two ways to package and run a local LLM.
GGUF:
- A file format developed by the llama.cpp project for storing quantized model weights in a single portable binary.
- Runs on any hardware: Mac, Linux, Windows, CPU-only machines, cloud GPUs.
MLX:
- Apple's open-source machine learning framework built specifically for Apple Silicon.
- Isn’t a file format like GGUF: converting a model with mlx_lm.convert produces a directory of safetensors shards, a config, and tokenizer files.
- Runs only on macOS.
When people say "MLX model," they mean a model converted to run via that framework, taking advantage of the unified memory architecture on M-series chips.
For users, the difference is speed and compatibility: GGUF works everywhere and loads fast on short tasks, MLX generates tokens faster on long outputs but only on Apple Silicon, and only if you pick the right runtime.
Does the inference app matter more than GGUF or MLX?
To some extent, yes. The runtime changes your speed no less than format on the same hardware and model throughout five runtimes on M1 Max 64GB:
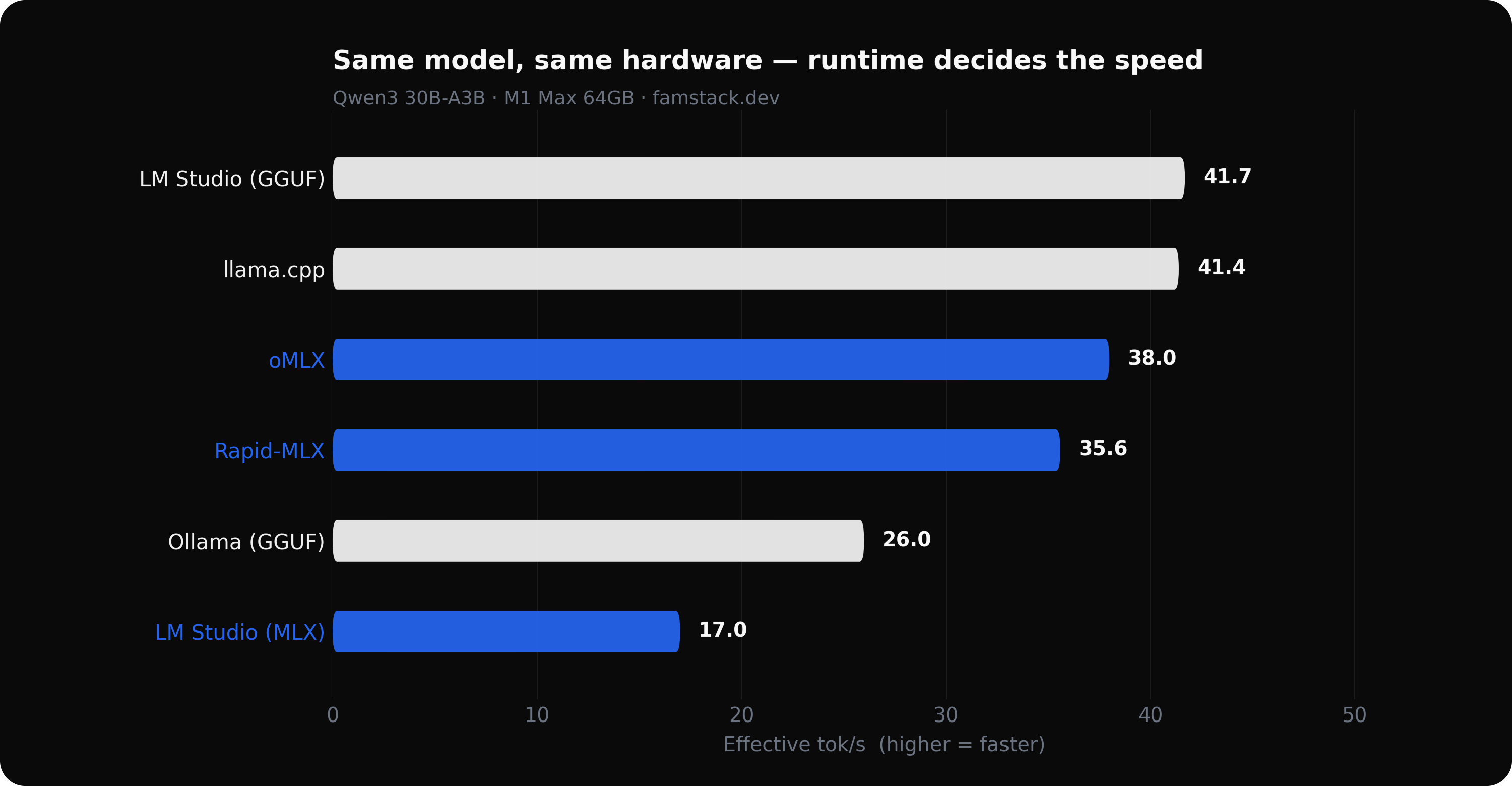
| Runtime | Format | Effective tok/s |
|---|---|---|
| LM Studio | GGUF (llama.cpp) | 41.7 |
| llama.cpp (from source) | GGUF | 41.4 |
| oMLX | MLX | 38.0 |
| Rapid-MLX | MLX | 35.6 |
| Ollama | GGUF (llama.cpp) | 26.0 |
| LM Studio | MLX | 17.0 |
Three things stand out from this data:
- The GGUF spread is 37%. LM Studio and raw llama.cpp are within noise at 41.7 vs 41.4. Ollama uses the same engine and runs 37% slower. Same GGUF files, same underlying code, different app.
- The MLX spread is 2.2x. LM Studio's MLX runtime hits 17.0 effective tok/s. oMLX reaches 38.0 on the same hardware with the same model. That gap is runtime overhead, not format.
- "MLX is 3x faster than Ollama" is a cherry-picked comparison. It puts the best MLX runtime (oMLX, 38.0) against the worst GGUF runtime (Ollama, 26.0). On equal runtimes, the difference is much smaller.
Ollama has one additional problem in multi-turn use: prompt caching doesn't work correctly. Each turn reprocesses the full conversation history from scratch. By turn 5 of an agent conversation, Ollama is computing context that a properly cached runtime would skip entirely.
How to get +40% on llama.cpp without switching formats
By default, llama.cpp generates one token per forward pass, so generation speed is limited by how fast the model can run one full pass regardless of hardware.
Atomic Chat (a runner for quick local LLMs setup without Terminal) uses Multi-Token Prediction (MTP) to deal with it: the model drafts several tokens at once and verifies them in a single step.
On MacBook Pro M5 Max: Gemma 26B ran 40% faster, Qwen 3.6 27B hit +40% with 90% draft acceptance rate. Same GGUF format throughout and the only variable was the runtime.
GGUF vs MLX: we ran our own test
To have independent data, we ran Qwen3-30B-A3B through both formats on a MacBook Pro M5 Max 64GB via Atomic Chat — same runtime for both.
Timing was wall-clock from send to last token, not the generation counter. M5 Max supports bf16 natively, so MLX runs without the software emulation that penalizes M1 and M2. The prefill gap showed up anyway.
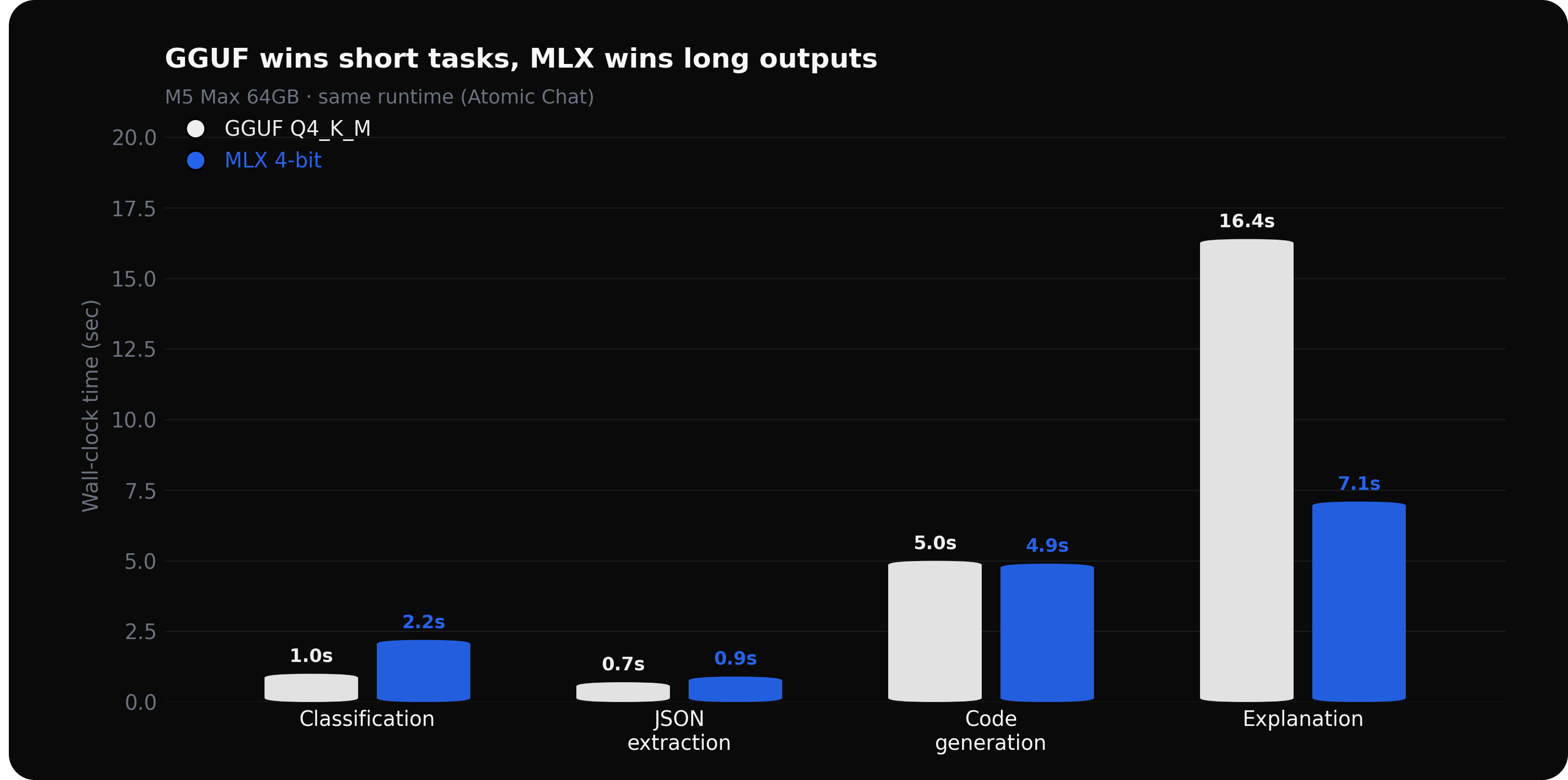
M5 Max wall-clock test: GGUF vs MLX on 4 prompt types
| Prompt type | GGUF Q4_K_M | MLX 4-bit |
|---|---|---|
| Short: classification | 1.0s | 2.2s |
| Short: JSON extraction | 0.7s | 0.9s |
| Long: code generation | 5.0s | 4.9s |
| Long: explanation (~300 tokens) | 16.4s | 7.1s |
Generation speed was close: 131 tok/s for GGUF, 125 tok/s for MLX. On both short prompts, GGUF finished faster and the difference comes from prefill. On code generation the formats are tied. The explanation prompt favored MLX, though output length varied, so treat that number as directional rather than definitive.
The pattern matches the previous benchmark: GGUF wins short, MLX wins long, and the gap is hardware-independent enough that M5 Max (Apple's most MLX-optimized chip) doesn't flip the short-task result.
Why does MLX show higher tok/s but can feel slower
The data above shows a consistent pattern: same generation speed but different wall-clock time on short tasks. The reason is that inference has two phases, and the counter in your app only measures one.
Prefill happens first: the model reads your entire input before producing any output. That pause before the first word appears is the prefill. Generation comes second, one token at a time. The tok/s counter in your UI measures only the second phase.
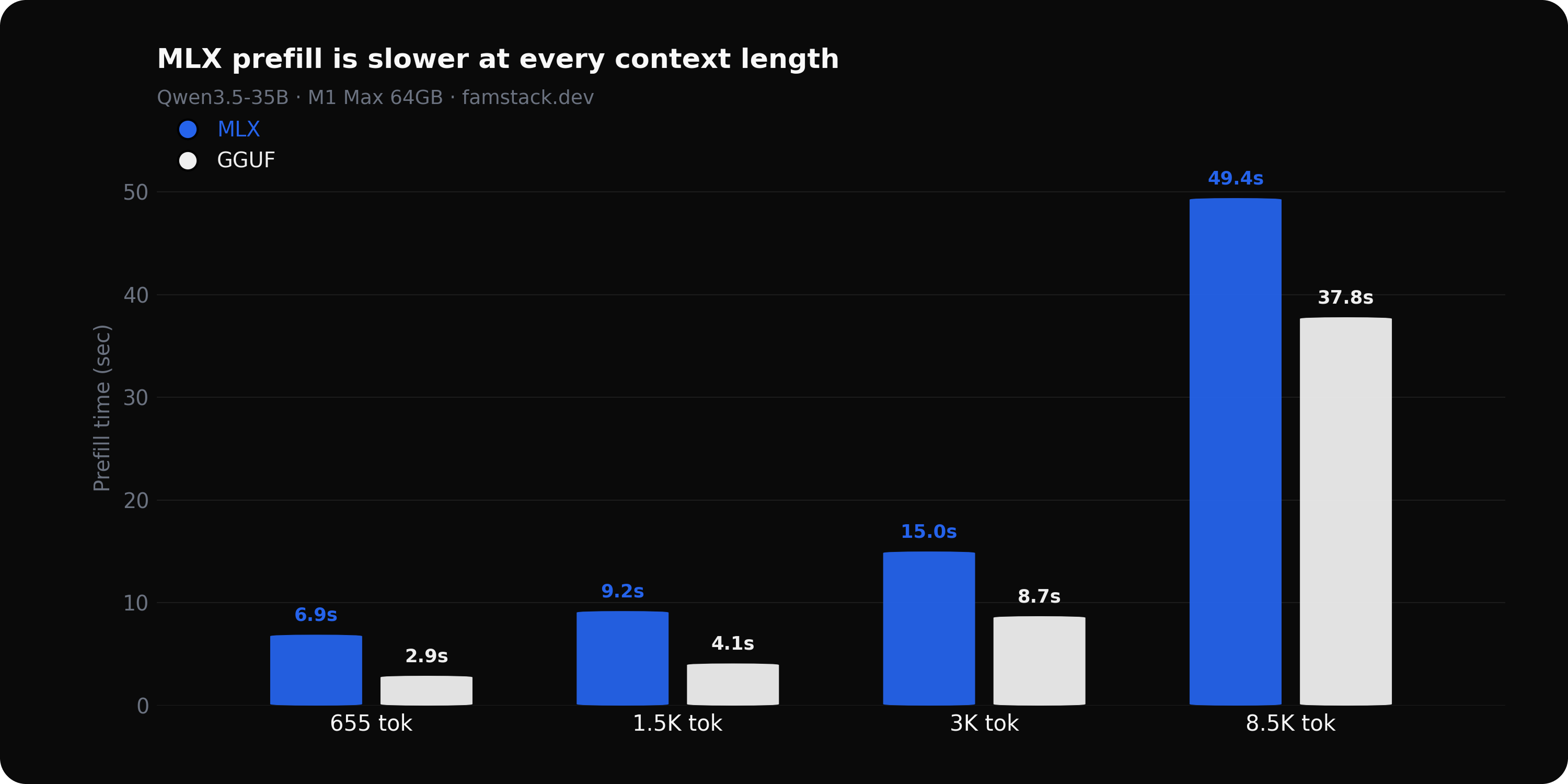
| Context size | MLX prefill (sec) | GGUF prefill (sec) | MLX effective tok/s |
|---|---|---|---|
| 655 tokens | 6.9 | 2.9 | 13 |
| 1.5K tokens | 9.2 | 4.1 | 12 |
| 3K tokens | 15.0 | 8.7 | 7 |
| 8.5K tokens | 49.4 | 37.8 | 3 |
MLX generates faster, but its prefill is slower:
- The tok/s counter in your app is blind to prefill. It starts counting only when the first token appears.
- At 655 tokens of context: MLX prefill takes 6.9s, GGUF takes 2.9s — before any output.
- On short tasks, GGUF finishes faster despite nearly identical generation speed, because the task is mostly prefill.
- Effective tok/s = output tokens ÷ total wall-clock time. That's the number that matches what you feel.
For a short response like a document classification or a tool call, the task is mostly over before MLX's generation advantage does anything useful.
Effective tok/s counts total time, prefill included. At 8,500 tokens of context, MLX spends 49 seconds reading input before generating anything — while the generation counter reads 57 tok/s.
When does the format choice influence your speed?
Model size: the 22B inflection point
MLX's speed advantage shifts with model size. A developer on M2 Ultra 192GB tested several models in LM Studio:
- Qwen 2.5 0.5B 4-bit: GGUF 79 tok/s, MLX 317 tok/s (4x faster on MLX)
- Mistral Small 22B 8-bit: GGUF 25.01, MLX 25.96 (tied)
- Qwen 2.5 72B 8-bit: GGUF 7.68, MLX 0.42 tok/s (18x slower on MLX)
In LM Studio, MLX falls back to CPU above ~22B parameters. That's when model layers stop fitting in GPU-accessible memory. GGUF handles this with the -ngl flag, which lets you manually set how many layers run on GPU. MLX has no equivalent control.
That said, the 22B ceiling is a LM Studio problem, not an MLX one. On M4 Max 128GB, a different MLX runtime (vllm-mlx) holds a 21% speed advantage over llama.cpp even at 30B parameters. Which runtime you use matters more than which format.
Chip generation: the bf16 problem on M1 and M2
Most MLX models on Hugging Face ship with bf16 weights. M1 and M2 don't support bf16 natively, so the chip runs it in software emulation during prefill. GGUF uses fp16, which runs at full hardware speed on both chips. One conversion fixes the bf16 prefill penalty on M1/M2:
On Gemma 3 12B at 8K context, prefill dropped from 114.4s to 68.9s after converting to fp16. No quality loss. On M3 and newer, bf16 runs natively – skip the conversion.
If you're on Atomic Chat, switching to a GGUF model quantized with TurboQuant sidesteps this entirely: GGUF uses fp16 weights, which M1 and M2 run at full hardware speed without any manual conversion.
Quantization quality: Q4_K_M vs uniform 4-bit
GGUF Q4_K_M allocates more bits to sensitive weight layers and fewer elsewhere, averaging 4.83 bits per weight. MLX 4-bit applies the same depth uniformly across all layers. The llama.cpp project measured perplexity impact on a 7B model:
| Format | Size | Perplexity increase vs F16 |
|---|---|---|
| Q4_0 (uniform, equivalent to MLX 4-bit) | 3.50 GB | +0.2499 |
| Q4_K_M | 3.80 GB | +0.0535 |
GGUF or MLX: quick reference
Favor GGUF:
- Short outputs: classification, Q&A, tool calls — the prefill advantage holds regardless of runtime
- Large models: -ngl splits layers between GPU and CPU, letting you run a 70B model on a 64GB Mac
- M1/M2 without the fp16 conversion above
- Situations where you need a model within hours of its release
Favor MLX:
- Long outputs on a good runtime (oMLX or mlx-lm): generation advantage is real for 250+ token responses
- Small models under 14B: 20–87% faster generation on M4 hardware
- RAM constraints: 7–13% less memory than GGUF at equivalent quantization
- On-device fine-tuning: MLX supports LoRA/QLoRA locally via mlx_lm.lora. llama.cpp is inference-only.
How to run GGUF faster: try running locally in Atomic Chat than in stock llama.cpp
Atomic Chat supports GGUF, MLX, and ONNX. Both formats are in the same model browser; switch without touching anything else.
What makes the difference versus stock llama.cpp:
- TurboQuant: custom GGUF quantization that preserves more quality at the same file size
- MTP (Multi-Token Prediction): patched llama.cpp that drafts several tokens per forward pass; tested at +40% on M5 Max
- No manual conversion: GGUF runs fp16 natively on any M-series chip, no bf16 workaround needed
In agent workflows, context builds up fast: system prompts, tool schemas, conversation history, JSON in every tool response. That's where MLX's prefill cost compounds most. On M1/M2, GGUF is the safer starting point. On M4/M5, the formats are close enough that your actual prompt patterns determine the result.
FAQ
Can MLX run GGUF files?
No. They use different runtimes and you download them separately. GGUF files come from llama.cpp-compatible model pages (Hugging Face, or anywhere hosting .gguf files). MLX models come from mlx-community on Hugging Face. There's no cross-format compatibility at runtime.
Are MLX models faster than GGUF on Mac?
On generation speed, yes — MLX is generally faster on Apple Silicon. On total wall-clock time for short tasks, often no. Prefill (reading your input before producing output) is slower on MLX, and on short tasks prefill is most of the wait. The result depends on task length, model size, chip generation, and which runtime you're using.
Why is Ollama slow if it uses the same engine as LM Studio?
Ollama wraps llama.cpp in a Go server with per-request overhead. That overhead is consistent — 37% slower than raw llama.cpp on both Gemma 12B and Qwen3 30B-A3B on M1 Max. On top of that, Ollama's prompt caching doesn't work correctly in multi-turn conversations, so each turn reprocesses the full history from scratch rather than caching it. The performance gap widens with each additional turn.
What's the difference between tok/s and effective tok/s?
tok/s in your UI measures generation speed only — the phase where tokens stream to the screen. Effective tok/s = output tokens / total wall-clock time, prefill included. On short tasks with large context, the two numbers can differ by 10x or more. A model showing 57 tok/s generation can deliver an effective throughput of 3 tok/s at 8,500 tokens of context — because it spent 49 seconds in prefill before generating anything.
Is GGUF Q4_K_M the same quality as MLX 4-bit?
No. GGUF Q4_K_M averages 4.83 bits per weight by assigning more bits to layers where precision matters most. MLX 4-bit is uniform. The perplexity difference is 4.7x at nearly the same file size (3.80 GB vs 3.50 GB on a 7B model). For large models (30B+) this barely registers on benchmarks. For smaller models under 8B, especially on coding tasks, it shows in output quality.
Should I convert MLX weights from bf16 to fp16 on M1/M2?
Yes. Most MLX models ship with bf16 weights, which M1 and M2 emulate in software during prefill. Converting to fp16 before running takes under a minute and recovers 40–70% of the prefill penalty for free. Run mlx_lm.convert --dtype float16 and point it at your local model directory. On M3 and newer chips, bf16 is natively supported and conversion is unnecessary.
Final word
Format debates miss the point: two apps running identical GGUF files on the same Mac differ by 37% in speed. An MLX runtime in LM Studio runs 2.2x slower than oMLX on the same model and hardware. Once you control for runtime, the format gap is narrow and it shrinks further on M4/M5.
Pick the runtime first. Then pick the format based on task length and model size. Short agentic tasks on M1/M2: GGUF is the safer default – long generation on newer hardware: test MLX on a runtime that handles it correctly.
Atomic Chat ships both formats in the same model browser, with TurboQuant and MTP already enabled to make your workflows even faster.
→ Run Your Local LLMs fast on Atomic Chat