
Qwen 3.7-Plus and MiniMax M3 – two models with an age difference of just 12-hours. Both Chinese, both claimed to be perfect for coding, especially autonomous – on agents like OpenClaw or Hermes. Their features also sound the same: multimodality, better at recognising visual content and, therefore, writing code from visual references.
Looking at these two – the logic question arises: which one is better in coding when it comes to real workflows? We broke down benchmarks, gave reader-friendly explanations, and actually ran tests ourselves.
What is Qwen 3.7-Plus
Before diving into comparison let’s see what’s new Qwen 3.7-Plus is like.
Qwen 3.7-Plus is a multimodal flagship released by Alibaba alongside its heavier sibling, Qwen 3.7 Max. Plus is the model you reach for when you need answers in seconds instead of a full thinking cycle and here’s features that let 3.7-Plus to be faster.
Qwen 3.7-Plus is:
- Multimodal. 2-weeks old Qwen 3.7 Max isn’t: if you want to chat with images, it won't process it – inevitably, you’d need to switch to a different model. And it would be Qwen 3.7-Plus: it can debug from your screenshots, operate UI elements, run CLI commands.
- Designed for everyday, high-volume workloads => trades reasoning depth for faster responses and lower token burn (should generate ~4x less tokens per response)
- Able to support tool invocation, self-programming, verification, testing, and autonomous iteration: it can write code, test it, find failures, and loop without human input.
What is MiniMax M3
MiniMax 3 is the latest frontier model from Chinese MiniMax, built on a new proprietary architecture – MiniMax Sparse Attention (MSA).
In contrast, MiniMax M3 has:
- MSA (MiniMax Sparse Attention): processes the KV cache in blocks rather than revisiting the full context on every step. At 1M tokens this runs at 1/20th the compute of their previous model: 9.7x faster prefill, 15.6x faster decode.
- Two-tier pricing: $0.60 input / $2.40 output per 1M tokens for requests under 512K; above that it doubles to $1.20 / $4.80. Among frontier models with comparable context windows, it's one of the cheapest.
- Open-weight: weights scheduled for HuggingFace around June 11, 2026. Self-hosted, it runs locally through tools like Atomic Chat with no API cost, data on-premises.
- Native multimodality: text, images, and video were part of training from day one, not added as a separate layer. It accepts all three as input simultaneously.
It's a strong fit for long autonomous runs and cost-sensitive workloads: less so if raw coding benchmark scores are your primary filter.
Qwen 3.7-Plus vs MiniMax M3: which is the best for coding
Qwen 3.7-Plus is cheaper than MiniMax M3:
The difference in pricing is not dramatic, though, if you evaluate your month usage, the gap mey be wider. Qwen 3.7-Plus wins on output (where coding spends most tokens). $3.75 vs $4.80 per 1M output tokens: that's a 22% difference. At 200M tokens/month (agentic team), Qwen saves $122/month vs M3.
Usual month token usage for regular and high-volume workloads is usually about 5M-20M if you’re on your own, and 50M-200M for agentic workflows or medium teams.
Monthly cost picture for solo MiniMax M3 / Qwen 3.7-Plus user:
- Light workloads (>5M): $17 for MinimaxM3 / $14 for Qwen 3.7-Plus
- Regular workloads (10M): $34 for MinimaxM3 / $28 for Qwen 3.7-Plus
- Heavy workloads (20M): $67 for MinimaxM3 / $55 for Qwen 3.7-Plus
→ Qwen 3.7-Plus can save you approximately $3-$12 on solo workflows
Monthly cost picture for agents/teams on MiniMax M3 / Qwen 3.7-Plus:
- Light workloads (50M): $168 for MinimaxM3 / $138 for Qwen 3.7-Plus
- Regular workloads (100M): $336 for MinimaxM3 / $275 for Qwen 3.7-Plus
- Heavy workloads (200M): $672 for MinimaxM3 / $550 for Qwen 3.7-Plus
→ Qwen 3.7-Plus can save you approximately $30-$122 if you work in a team / on agents
Coding: where each model wins
On terminal and shell work, Qwen leads. Terminal-Bench 2.0: 70.3 vs 66.0. It also has documented scores on multilingual codebases (SWE-Bench Multilingual, polyglot fixes: 75.8%) and API/function calling (BFCLv4: 72.9%) – both areas where M3 has no published equivalent.
For reading UI screenshots, designing mockups alongside code, Qwen 3.7-Plus's multimodal numbers are specifically strong there: ScreenSpot Pro 79.0, above GPT-5.4 and Gemini 3.1 Pro on the same evaluation.
M3's is better in anything running longer than an hour: on a CUDA kernel optimization task, M3 made 1,959 tool calls over 24 hours and kept improving through submission 145 of 147 (most models stop improving after 30). SWE-Bench Pro tests real GitHub issue resolution (reading a codebase, identifying a bug, writing a fix) not contrived functions. M3 scores 59.0% vs Qwen's 57.6%; small gap, but on the benchmark most similar to actual software engineering work.
For tasks involving web research mid-run, BrowseComp 83.5 puts M3 at the top of published scores. Most models stop improving after 30. That's a direct test of context coherence under load, not a synthetic benchmark.
Multimodal capabilities and tool use
Qwen 3.7-Plus is better in images:
Qwen 3.7-Plus takes image input and performs well on it. ScreenSpot Pro (locating specific UI elements in a screenshot, like "where is the submit button") scores 79.0%, above GPT-5.4 and Gemini 3.1 Pro on the same evaluation.
RealWorldQA: 86.9%. If your workflow involves handing the model a Figma mockup, an architecture diagram, or a screenshot of a broken UI and asking it to generate or fix code, this is where Qwen 3.7-Plus is concretely useful – it reads the image and reasons about the code.
MiniMax M3 is stronger in videos:
M3 adds video input and desktop computer use via MiniMax Code. Computer use is the meaningful part: the model can take actions – navigate a browser, click, fill forms instead of describing what it sees.Unlike Qwen 3.7-Plus that can look at a screenshot and tell you what's wrong, M3 can watch a screen recording of a bug reproducing, open the relevant file and fix it.
Minimax M3 vs Qwen 3.7-Plus: Real-World Performance
Task we set for models: “Build a polished, fully self-contained waitlist landing page in a single HTML file (no external CSS frameworks, vanilla JS only). Product: "Nova" — an AI writing assistant for solo founders.”
The hero
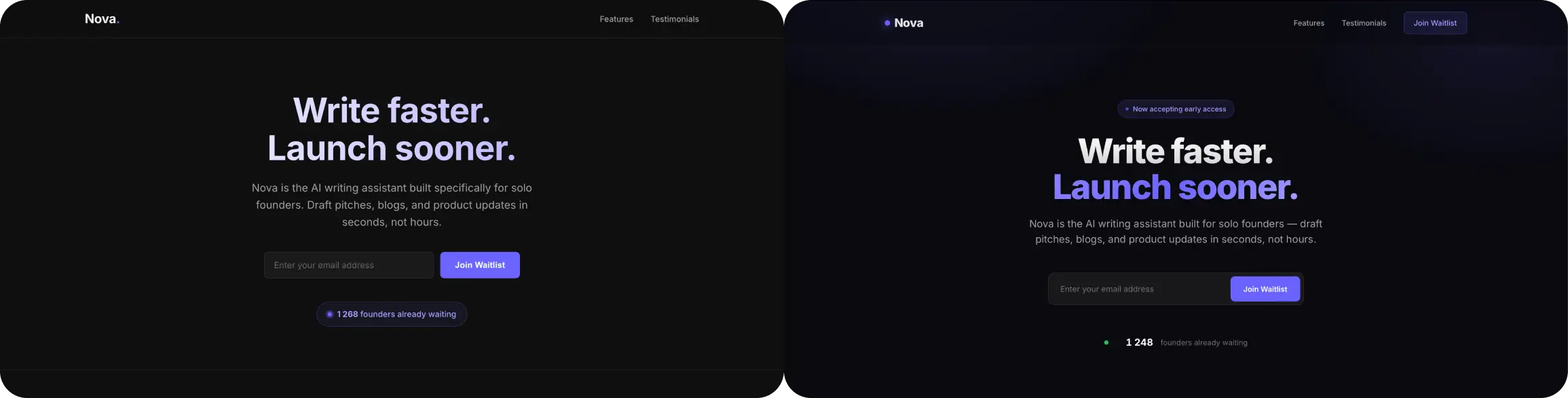
Qwen 3.7-Plus loaded on first click: clean black background, white headline, form that works – no drama.
version had to be fixed first: it delivered CSS and JavaScript with no HTML body, which means it wasn't a page, it was parts of a page. Once reassembled, though, the difference is more visible: the right side has a purple glow behind the hero, an accent color on the second line of the headline, a live badge. The left side is flat.
So, MiniMax M3 is way better in designing, however, Qwen 3.7-Plus gave us clearer code.
The features
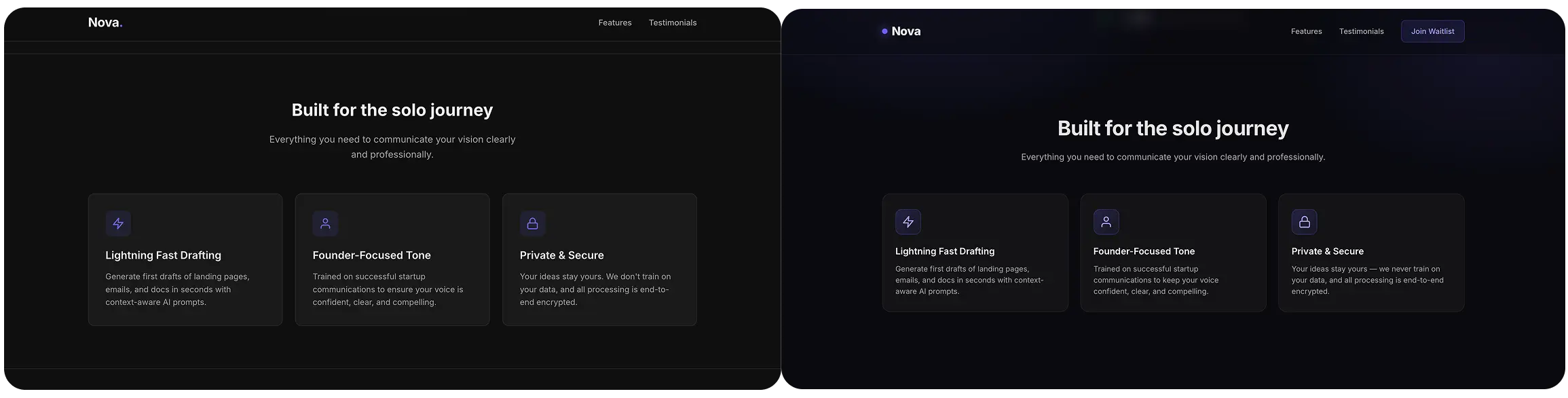
Both reached for the same three cards, the same icons, roughly the same copy. MiniMax's cards sit on a slightly warmer dark surface with more breathing room. Qwen's are functional but compressed.
Neither made a wrong turn here, but MiniMax M3 again made a better appearance.
The testimonials
.webp)
Qwen puts the quote first, attribution at the bottom. Completely standard card layout.
MiniMax flips it: name and role at the top, quote below. Feels more like a real review and less like a widget. The avatar gradients are also distinct per person on the right (blue, pink, green), while Qwen used the same purple for all three.
The result: Qwen shipped a working page, and MiniMax shipped a better-looking one that needed surgery to run. If this were a production code review, Qwen's PR gets merged and MiniMax's gets sent back with "where's the HTML?"
When to pick which
Best model for bash scripts and shell automation
Qwen 3.7-Plus. Terminal-Bench 2.0: 70.3 vs M3's 66.0. The largest benchmark gap between the two models, and the most consistent one.
Best model for autonomous coding agents that run unsupervised
MiniMax M3. On a 24-hour GPU kernel optimization task, it made 1,959 tool calls and hit its best result on submission 145 of 147. Most other models stopped improving after submission 30 – the architecture difference is real here.
Best model for production code that needs to run without fixes
Qwen 3.7-Plus. We gave both models the same prompt with no guardrails: Qwen's output loaded on first click, M3's arrived as CSS and JS with no HTML body – better looking, but not a runnable page. Though, rerunning prompts on MiniMax M3 cost almost nothing, so it’s also a solid choice.
Best model for vibe coding and UI prototyping
MiniMax M3. When design quality matters more than first-run correctness, M3's output is stronger. It also handled a napkin sketch-to-playable-game task in a single pass (6,920 input tokens, $0.028 total cost).
Best model for a self-hosted private coding assistant
MiniMax M3. Open-weight release expected around June 11, 2026: runs locally, no API, code never leaves the machine. Qwen 3.7-Plus has no local deployment path.
FAQ
Is Qwen 3.7-Plus the same as Qwen 3.7 Max?
No. Max is text-only; Plus adds image input. Most coding benchmarks and comparisons you'll find in the wild reference Max. If the article or thread doesn't specify, assume it's Max.
Which model is better for which type of coding?
Qwen 3.7-Plus: terminal/shell scripting (Terminal-Bench 70.3 vs 66.0), multilingual codebases, API/function calling, and workflows that involve reading UI screenshots or diagrams. M3: real-world GitHub issue resolution (SWE-Bench Pro 59.0% vs 57.6%), long autonomous runs where context fills up over hours, and coding tasks that require pulling external information mid-session. For debugging, test generation, or code review, neither model has task-specific benchmark data published.
Can I run MiniMax M3 locally?
Not at launch. Weights were announced for HuggingFace release within ~10 days of June 1, 2026. Once available, you can self-host through a local model runner like Atomic Chat and keep inference fully on-premises. But you still can try MiniMax M3 on Atomic Chat through API – almost no hardware requirements and faster output.
Which is cheaper for API coding workloads?
Qwen 3.7-Plus: $3.75/1M output vs M3's $4.80/1M. Input is nearly identical. Since coding generates more output than input, Qwen wins on API cost. Self-hosted M3 is cheaper once the open-source weights ship.
Bottom line
Under identical conditions, Qwen shipped code that ran and M3 shipped code that looked better but needed fixing before it would load. That actually tracks with the benchmark picture: Qwen wins on correctness-heavy tasks, M3 on longer and more ambitious ones. In a nutshell, if you tolerant towards rerunning your prompts: it's not costly and actually produces good job, especially with more specific prompts.
The open-source question for some matters more than the pricing gap. Once M3's weights land on HuggingFace, running it locally costs effectively nothing. But the cost isn't the main draw: for developers handling sensitive data, the point is that nothing leaves the machine. M3 has no API, doesn't send your data to third-party servers. Qwen 3.7-Plus, unfortunately, has no local path at all.
For API use right now: Qwen is cheaper and ships working code. If local deployment or data privacy is on your roadmap, M3 is worth building toward before the weights even arrive.





